英为财经Investing.com简介
英为财情(Investing)是全球第三大财经门户网站,提供了全球股票、股指、外汇、期货、债券、数字货币等超十万种金融资产品种的实时行情报价,涵盖全球70多个国家和地区。还提供多种投资工具,如财经日历、财报日历、美联储利率观测器、选股器、技术指标分析。英为财经的金融数据库比较全面,且大部分都是免费提供出来,这就给我们散户做量化提供了便利。下面我将利用爬虫对我们需要的股票数据进行获取,并记录下爬虫遇到的问题和解决方法。
数据获取的目标
由于之前写过一个不同市场套利的事件驱动型策略,大致思路是寻找在欧洲股市上市并在美国有ADR的股票,然后利用欧洲和美国两地股票市场不同的交易时间来定义事件类型,分别为正面事件、中性事件和负面事件,然后判断各类事件对股价的影响,寻找套利机会。这里ADR是American Depositary Receipts的缩写,意为美国存托凭证。ADR是一种由美国银行发行的,代表在美国境外的外国公司股票的证券产品。ADR的发行和交易是在美国证券交易所进行的。下面是当时简单的策略回测图:
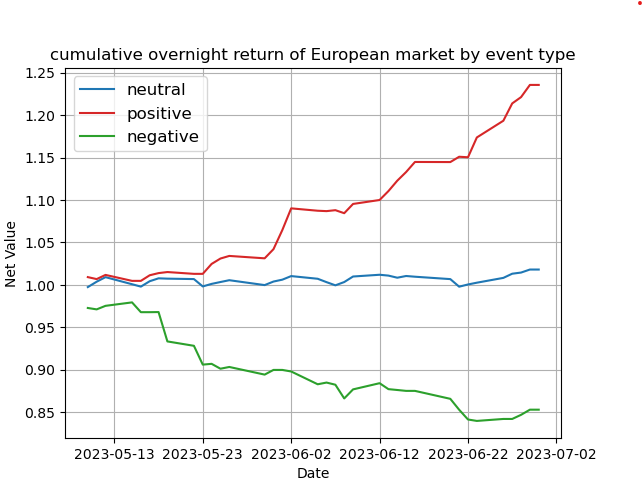
可以发现不同事件对股价具有明显的影响。本次数据获取的目标是港股对应的ADR的历史数据。官网链接为:https://cn.investing.com/equities/hong-kong-adrs
数据获取步骤
1、安装相关依赖
import cloudscraper
import pandas as pd
import time
import math
2、获取港股ADR列表
首先进入官网,进入开发者模式,寻找网页获取数据发送的请求。
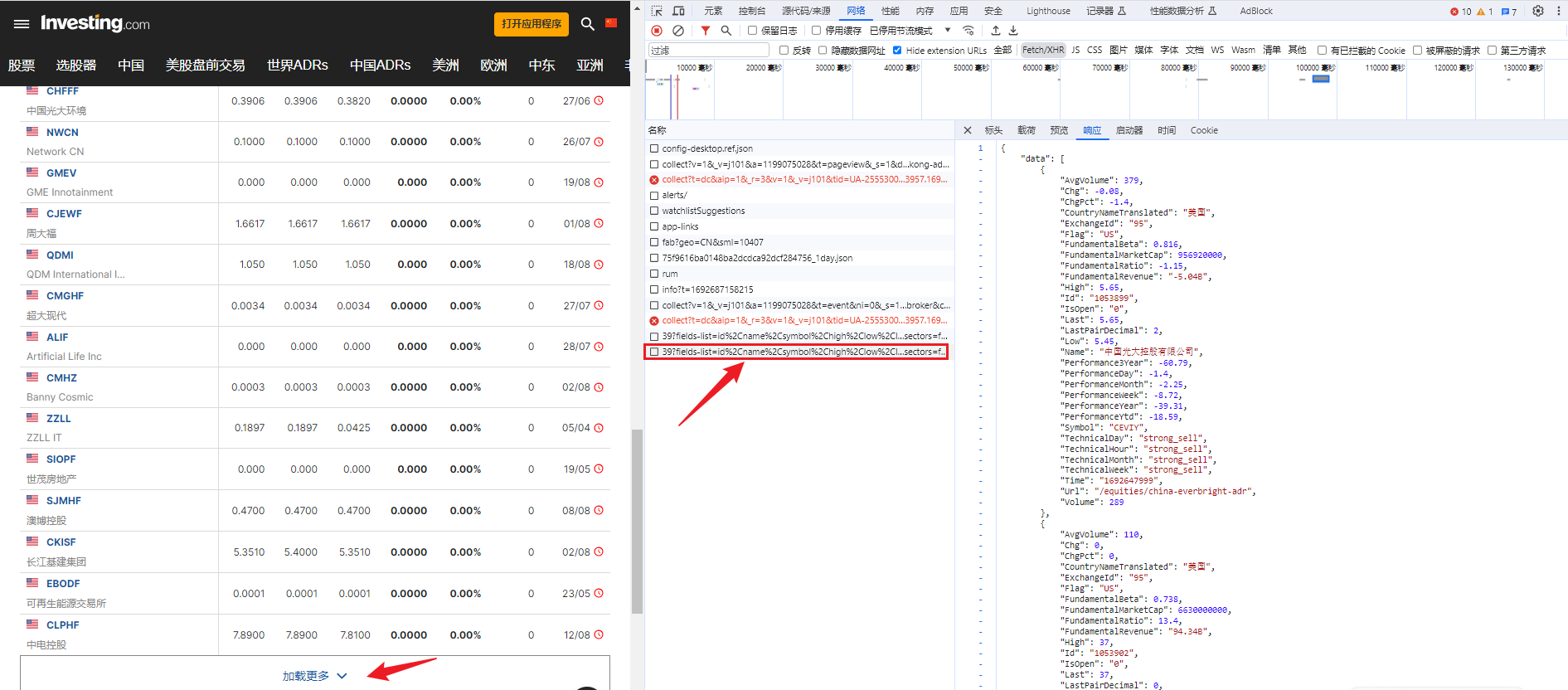 之后成功定位到包含列表数据请求链接。链接为:
'https://api.investing.com/api/financialdata/assets/adrEquitiesByCountry/37?fields-list=id%2Cname%2Csymbol%2Chigh'%2Clow%2Clast%2ClastPairDecimal%2Cchange%2CchangePercent%2Cvolume%2Ctime%2CisOpen%2Curl%2Cflag%2CcountryNameTranslated%2CexchangeId%2CperformanceDay%2CperformanceWeek%2CperformanceMonth%2CperformanceYtd%2CperformanceYear%2Cperformance3Year%2CtechnicalHour%2CtechnicalDay%2CtechnicalWeek%2CtechnicalMonth'%2CavgVolume%2CfundamentalMarketCap%2CfundamentalRevenue%2CfundamentalRatio%2CfundamentalBeta&country-id=&page=3&page-size=50&include-major-indices=false&include-additional-indices=false&include-primary-sectors=false&include-other-indices=false&limit=0'
之后成功定位到包含列表数据请求链接。链接为:
'https://api.investing.com/api/financialdata/assets/adrEquitiesByCountry/37?fields-list=id%2Cname%2Csymbol%2Chigh'%2Clow%2Clast%2ClastPairDecimal%2Cchange%2CchangePercent%2Cvolume%2Ctime%2CisOpen%2Curl%2Cflag%2CcountryNameTranslated%2CexchangeId%2CperformanceDay%2CperformanceWeek%2CperformanceMonth%2CperformanceYtd%2CperformanceYear%2Cperformance3Year%2CtechnicalHour%2CtechnicalDay%2CtechnicalWeek%2CtechnicalMonth'%2CavgVolume%2CfundamentalMarketCap%2CfundamentalRevenue%2CfundamentalRatio%2CfundamentalBeta&country-id=&page=3&page-size=50&include-major-indices=false&include-additional-indices=false&include-primary-sectors=false&include-other-indices=false&limit=0'
在请求头中可以发现为GET请求,GET请求一般都比较简单,只需要传入header和cookie就能直接拿到数据。但是这个网站存在一个小的反爬机制:cloudflare
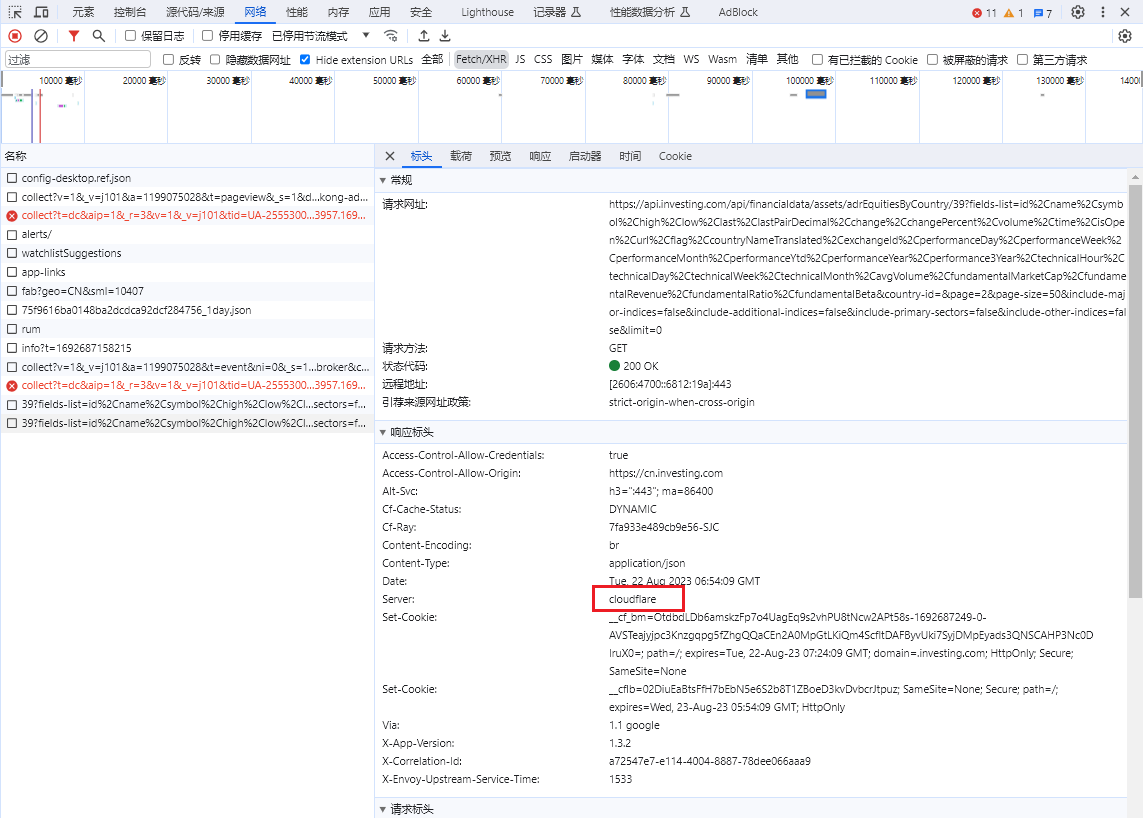
cloudflare的5S盾,常常阻碍爬虫正常访问网站。在进行数据采集时,Python爬虫经常会遇到cloudflare返回的403错误,在该网站就是大量使用了cloudflare来反爬。
要绕过这个5秒盾非常简单,cloudscraper这个库就可以完美解决。下面给出安装代码:
pip install cloudscraper
获取ADR列表的完整代码如下:
# 获取国内公司在美国上市的所有ADR名称
def get_ADR_id():
headers = {
'Origin': 'https://cn.investing.com',
'Referer': 'https://cn.investing.com/',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 '
'Safari/537.36',
'Domain': '.investing.com',
'Authorization': 'Bearer',
}
scraper = cloudscraper.create_scraper(browser={
'browser': 'firefox',
'platform': 'windows',
'mobile': False,
'headers': headers # 将headers参数传递给创建scraper的函数
})
# 获取页面总数
result = scraper.get(
本主题为课程学员专享,成为股票量化投资课程学员后可免费阅读
成为学员