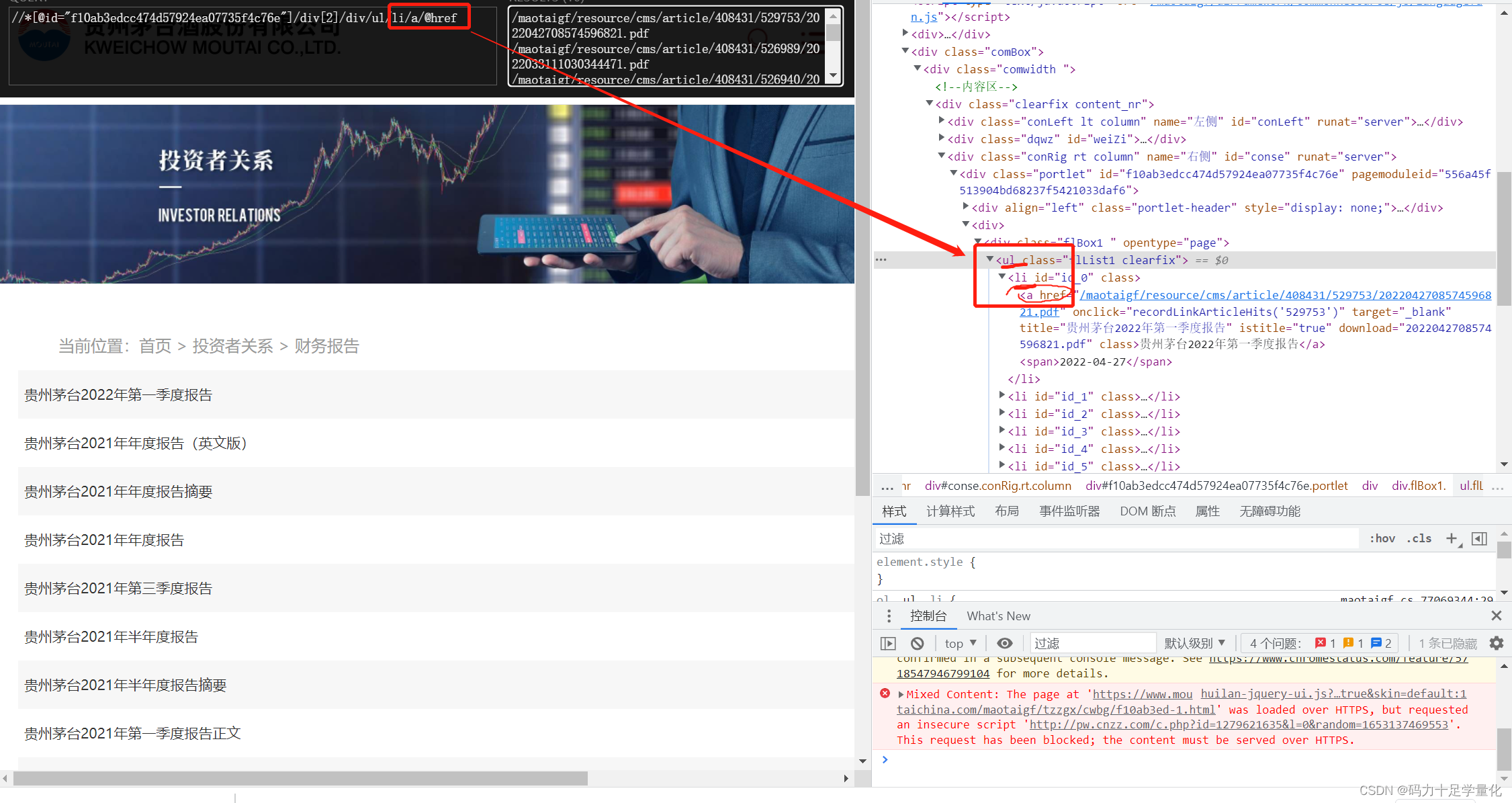
for i in range(len(href_list)):
print(i)
# 网址拼接
url="https://www.moutaichina.com/"+href_list
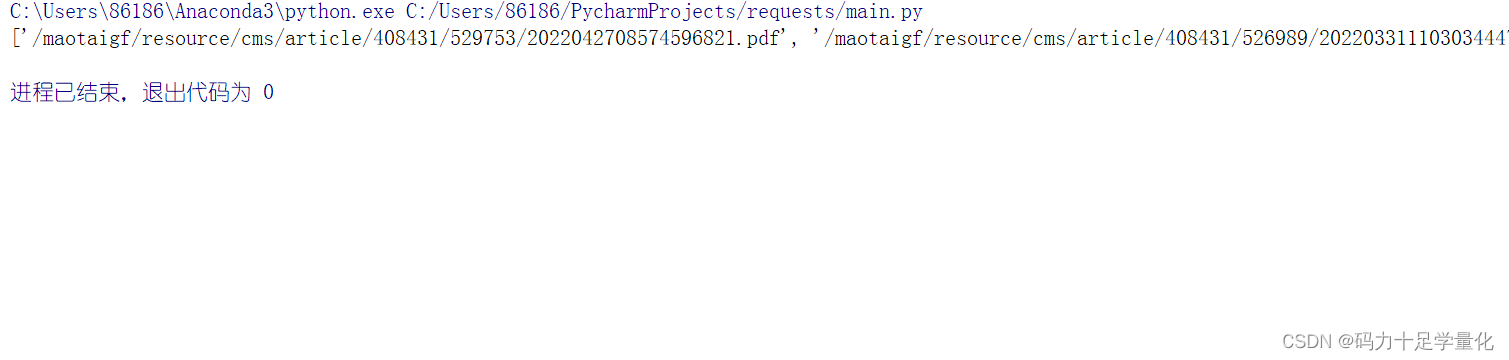
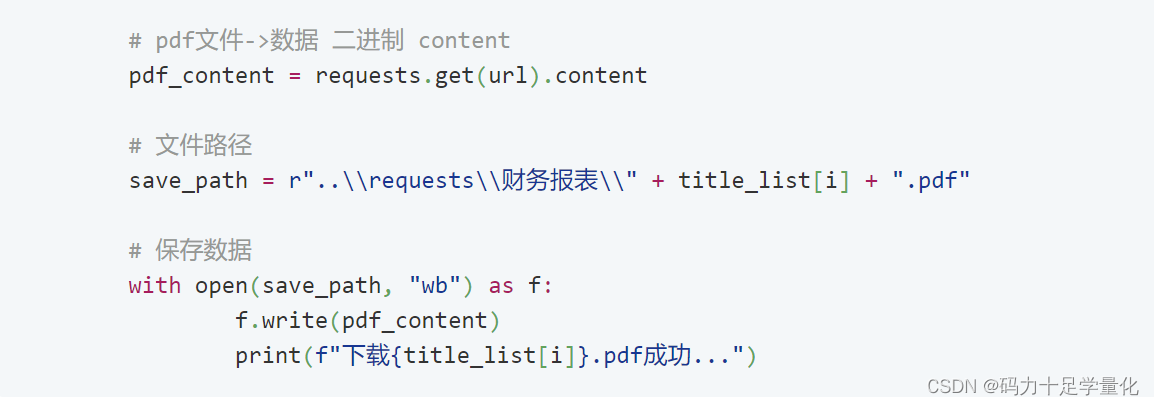
# pdf-->数据 二进制数据.content
pdf_content=requests.get(url).content
with open(save_path,"wb") as f:
"""
写入二进制形式
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
========= ===============================================================
"""
f.write(pdf_content)
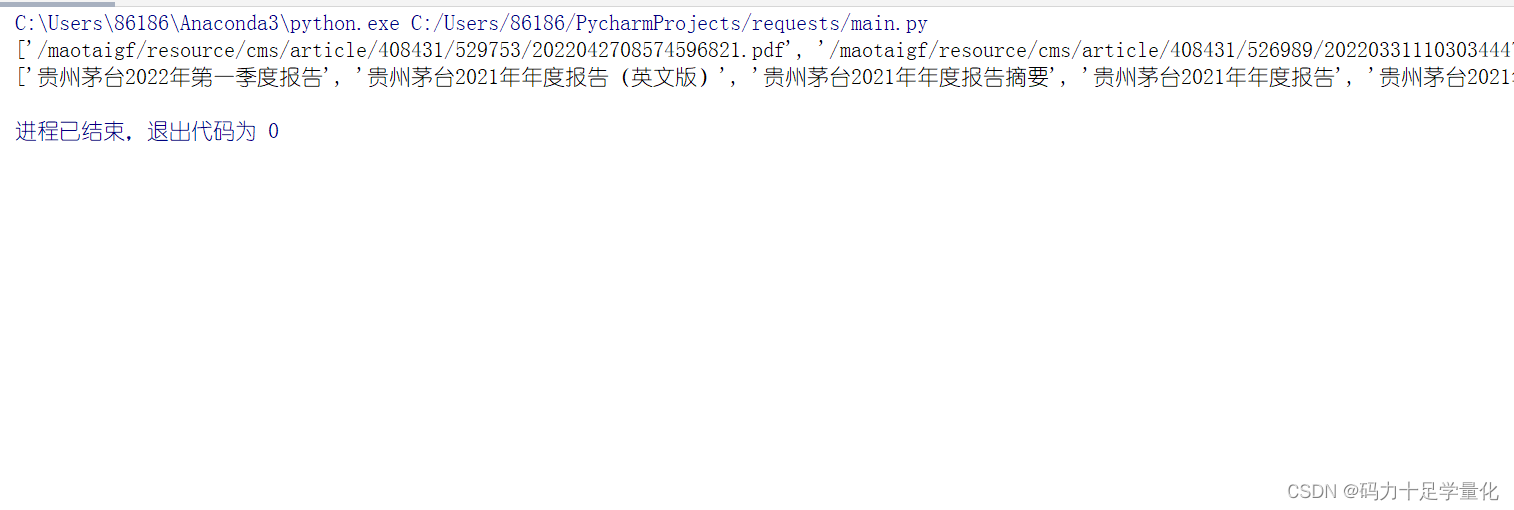
print(f"下载{title_list}.pdf成功...")

 )
) )
) )
) )
) )
) )
) )
) )
)